
OANet
Learning Two-View Correspondences
1. Introduction
-
Until recently, most of geometric matching pipeline focus on learning local feature detectors and descriptors.
-
Previous works exploited PointNet-like architecture and Context Normalization(PointCN)
CONS
-
apply MLP on each point individually and cannot capture the local context.
邻居像素的也有类似的运动 有利于outlier rejection
-
Context Normalization编码全局信息,忽略了不同点之间的特性
One of the challenges in mitigating the limitations above:
- sparse matches have no well-defined neighbors
- the relation are unordered and have no stable relations to be captured.
-
-
draw inspiration from the hierarchical representations of GNN
- generalize DiffPool: permutation-invariant and to capture the local context
-
threefold contributions:
- DiffPool and DiffUnpool layers to capture the local context of unordered sparse correspondences in a learnable manner
- Order-Aware Filtering block: exploits the complex global context of sparse correspondences.
- accuracy
2. Related work
2.2 Outlier Rejection
-
putative correspondences established by handcrafted or learned features contain many outliers.
-
RANSAC: most popular outlier rejection method
PointCN: reformulated the outlier reection task as an inlier/outlier clasfication problem and an essential matrix regression problem
Context Normalization: can drastically improve the performance.
-
Geometric Deep Learning deals with data on non-Euclidean domains.
和点云不同的是,sparse correspondences have no well-defined neighbors.
3. Order-Aware Network
3.1 Formulation
GOAL: Given image pairs, remove outliers
- using features to find nearest neighbors in the other image.
- outlier rejection
- an essential matrix can be recovered
INPUT
-
- is a correspondence and are the coordinates of keypoints in these two images.
Architecture
-
- Z is the logit values for classfication
- is a permutation-equivariant neural network and denotes the network parameters.
- w is the weights of correspondences.
3.2 Differentiable Pooling Layer
The unordered input correspondences require network to be permutation-equivariant, so PointNet-Like architecture was used.
- However, PointNet-like architecture has the drawback in capturing the local context because there is no direct interaction between points.
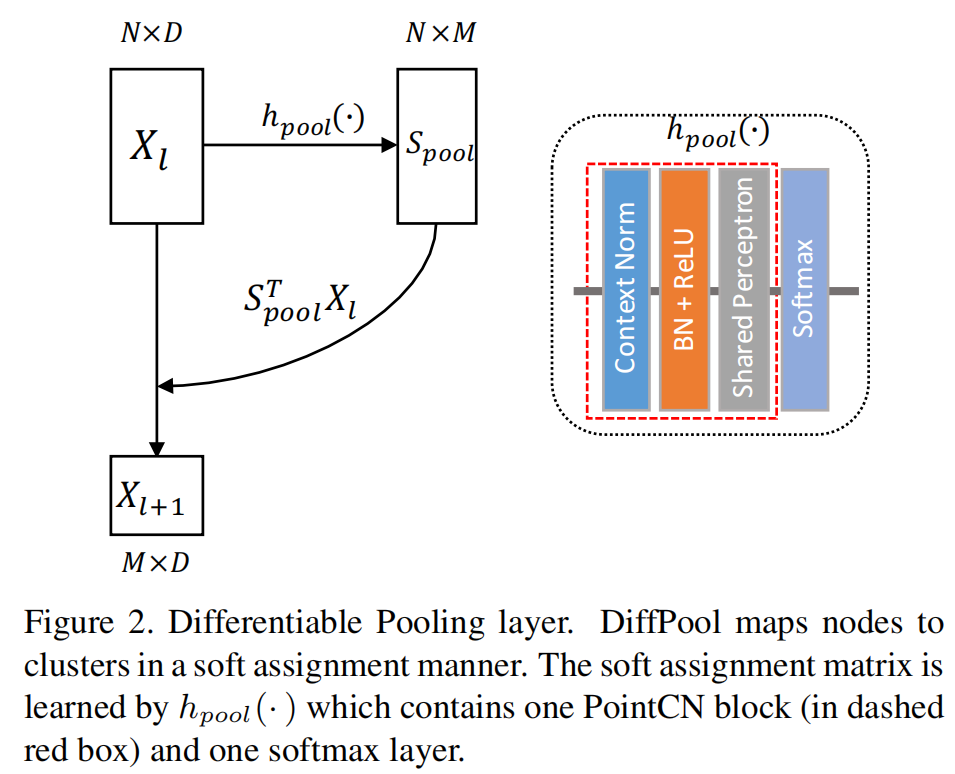
-
Rather than employing a hard assignment for each node, the DiffPool layer learns a soft assignment matrix.
, Diff-Pool maps N nodes to M clusters:
- is one PointCN block here.
- softmax layer is applied to normalize the assignment matrix along the row dimension.
Permutation-invariance
DiffPool is permutation-invariance:
- Since both and softmax are permutation-equivariant functions, so
once the network is learned, no mater how the input are permuted, they will be mapped into clusters in a particular learned canonical order
3.3 Differentiable Unpooling Layer
-
to upsample the coarse represention and build a hierarchical architecture.
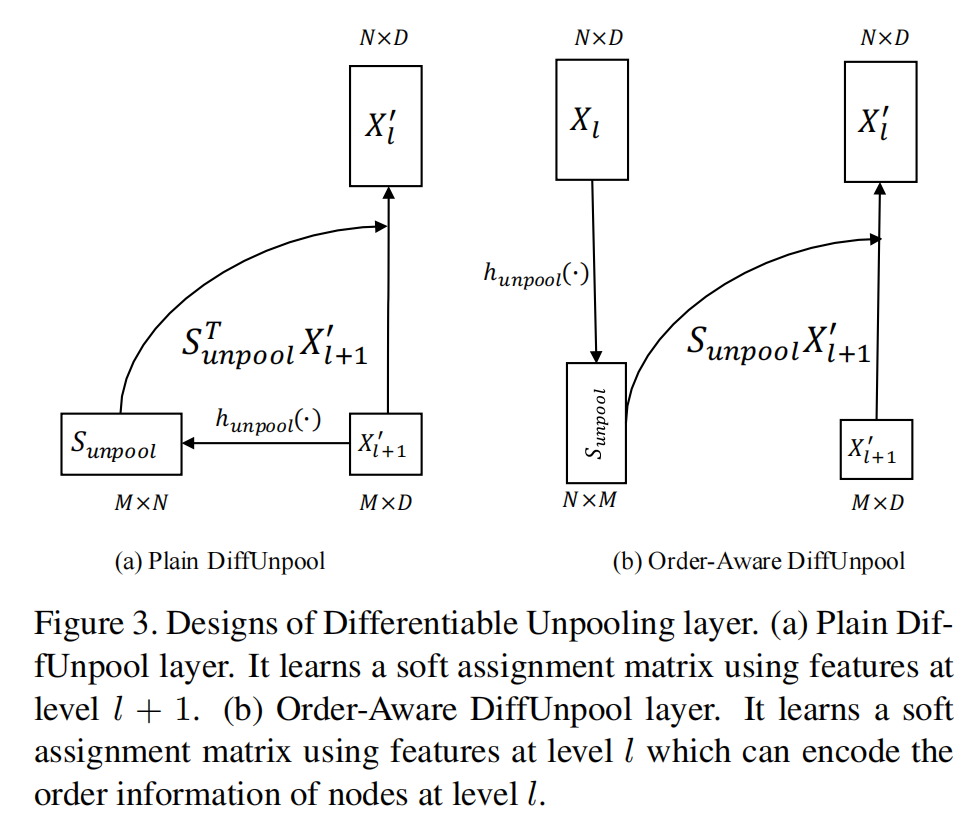
-

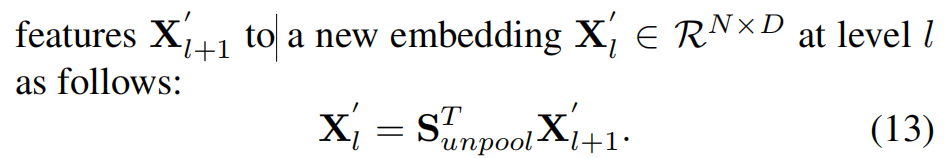
-
3(a) cannot recover the original spatial order of because of permutation-invariant operation, and only utilizes information at level
-
3(b) advise it as an Order-Aware DiffUnpool layer
因为编码了序列信息,所以学出来的也会保持序列特征。
-
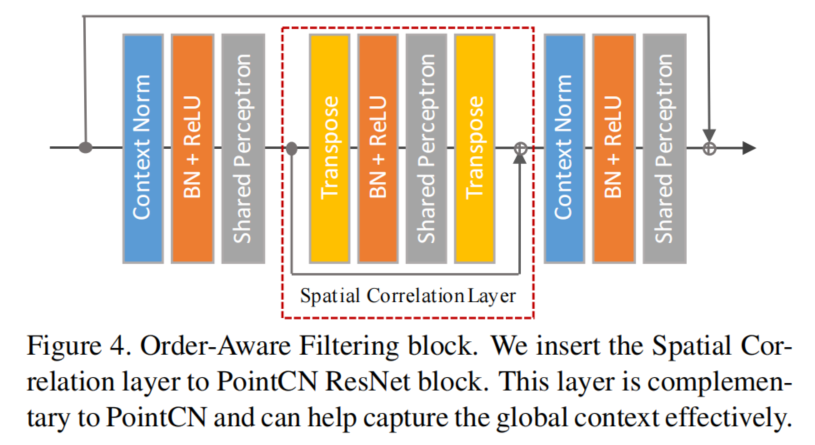
3.4 Order-Aware Filtering Block
Here we propose a simple but more effective operation than PointCN block, which is called Spatial Correlation layer to explicitly model relation between different nodes and capture the complex global context.
-
the weights are shared along the channel dimension
-
the spatial correlation layer is orthogonal to PointCN, since one is along the spatial dimension and the other is along the channel dimension.
-
Spatial Correlation layer is implemented by tranposing the spatial and channel dimensions of features.
After the weight-sharing perceptrons layer, we transpose features back.
-
Note that before the DiffPool layer, we cannot apply the Spatial Correlation layer on the feature maps as the input data is unordered and there is no stable spatial relation to be captured.
