
DiffPool
Hierarchical Graph Representation Learning
Abstract
- However, current GNN methods are inherently flat and do not learn hierarchical representations of graphs.
- DIFFPOOL, a diferentiable graph pooling module that can generate hierarchical representations of graphs and can be combined with various GNN architectures.
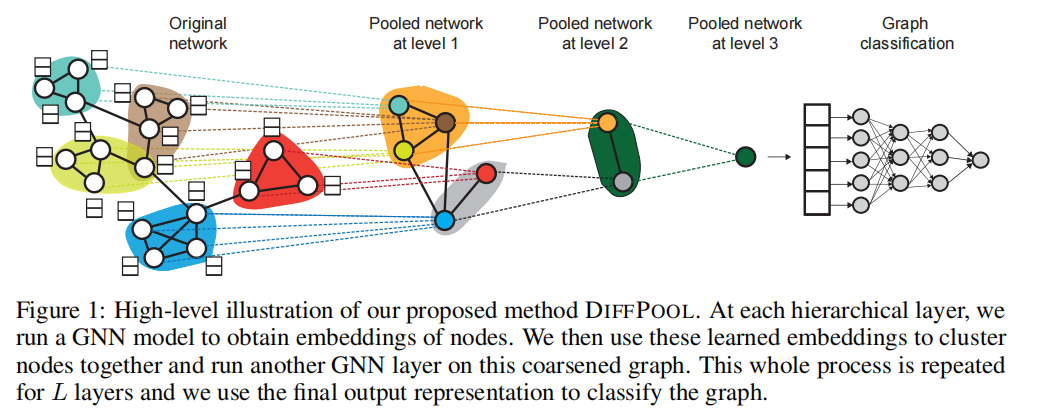
- the input nodes at the layer GNN module correspond to the clusters learned at the layer GNN module.
1. Introduction
-
This lack of hierarchical structure is especially problematic for the task of graph classifification, where the goal is to predict
the label associated with an entire graph.traditional globally pool such as summation or network ignores any hierarchical structure that might be present in the graph.
3. Proposed Method
3.1 Preliminaries
-
- is the adjacency matrix
- is the node feature matrix assuming each node has d features.
-
Graph neural networks
general “message-passing” architecture:
- are the node embeddings computed after k steps of GNN
- : message propagation function
- are initialized with
-
A full GNN module will run K iterations to generate the final output node embeddings
For, simplicity, use to denote an arbitrary GNN module.
3.2 Differentiable Pooling
Pooling with an assignment matrix
-
- Each row of corresponds to one at the nodes at layer l
- Each column corresponds to one at the nodes at layer l+1.
-
DIFFPOOL layer
Learning the assignment matrix
- use a standard GNN module to generate Z:
-
generate an assignment matrix:
- softmax function is applied in a row-wise fashion
- the output dimension of 是超参数
-
Note that these two GNNs consume the same input data but have distinct parameterizations and play
separate roles:
-
The embedding GNN generates new embeddings for the input nodes at this layer,
-
while the pooling GNN generates a probabilistic assignment of the input nodes to clusters.
-
Permutation invariance
in order to be useful for graph classifification, the pooling layer should be invariant under node permutations.
For DIFFPOOL we get the following positive result, which shows that any deep GNN model based on DIFFPOOL is permutation invariant.
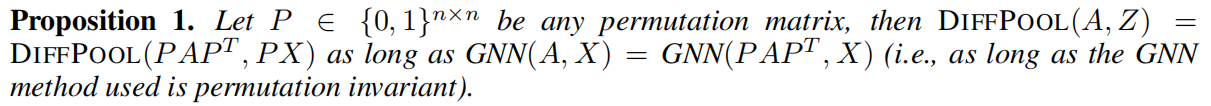
3.3 Auxiliary Link Prediction Objective and Entropy Regularization
注意到在更新A的时候非凸,可能回落到局部极值:
-
at each layer , minimize
-
the output cluster assignment for each node should generally be close to a one-hot vector, therefore we regularize the entropy of the cluster assignment by minimizing:
- H denotes the entropy function
- is the i-th row of S.
4. Experiment
sensitivity of the pre-defined Maximum Number of Clusters:
-
With larger C, the pooling GNN can model more complex hierarchical structure.
trade off!
- very large C results in more noise and less efficiency.