
EnlightenGAN
Method
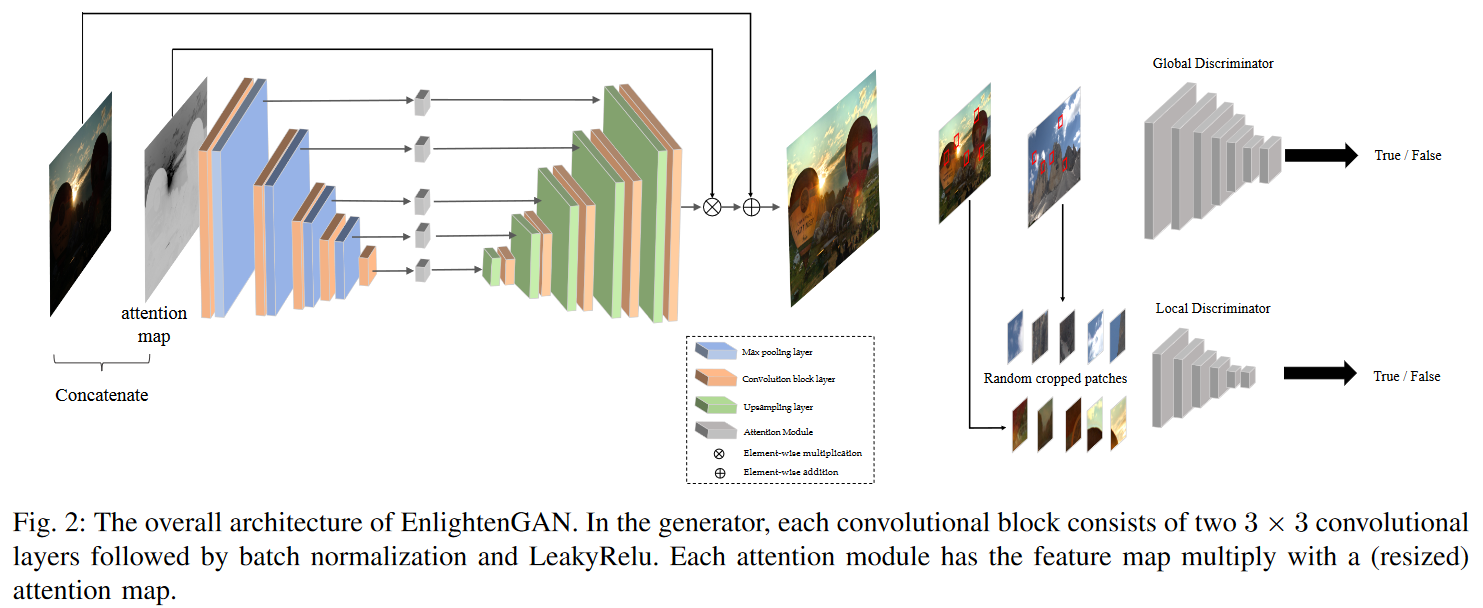
- As shown in Fig. 2, our proposed method adopts an attention-guided U-Net as the generator and uses the dual-discriminator to direct the global and local information.
- We also use a self feature preserving loss to guide the training process and maintain the textures and structures.
- U-Net generator is implemented with 8 convolutional blocks.
- Each block consists of 2 convolutional layers, followed by LeakyReLu and a batch normalization layer.
- At the upsampling stage, replace the standard deconvolutional layer with one bilinear upsampling layer + one convolutional layer to mitigate the checkboard artifacts.
A. Global-Local Discriminators
-
a small bright region in an overall dark background, the global image discriminator alone is often unable to provide the desired adaptivity.
-
In addition to the image-level global discriminator, we add a local discriminator by taking randomly cropped patches from both output and real normal-light images, and learning to distinguish which are real.
Ensures all local patches of an enhanced images look like realistic normal-light ones
-
对于global discriminator, we utilize the relativistic discriminator structure

replace the sigmoid function with the least-square GAN loss
-
For the local discriminator, we randomly crop 5 patches from the output and real images each time.
-
B. Self Feature Preserving Loss
pretrained VGG perceptual loss: 但是perceptual loss 对intensity不敏感。
new loss:
- : input low-light image
- : the generator’s enhanced output.
- : the feature learned by VGG-16 pre-trained on ImageNet.
overall loss function
C. U-Net Generator Guided with Self-Regularized Attention
-
Intuitively, in a low-light image of spatially varying light condition, we always want to enhance the dark regions more than bright regions.
-
We take the illumination channel I of the input RGB image, normalize it to , and then use as our self-regularized attention map.
and then resize to fit each feature map and multiply it with all intermediate feature maps.